Kenali foto, lagu, kebiasaan pengguna. Dengan kecerdasan buatan itu sudah mungkin. Tetapi mengapa itu penting, dan bagaimana pengaruhnya terhadap cara hidup kita?
Sebelum menjawab pertanyaan ini, kita perlu mengambil langkah mundur untuk menjelaskan perbedaan antara Kecerdasan Buatan (KEPADANYA), Pembelajaran mesin (ML) dan Belajar mendalam (DL), istilah yang sering dikacaukan tetapi dengan arti yang tepat.
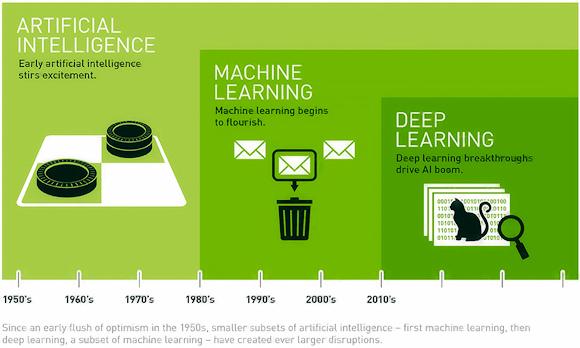
Untuk menjelaskan ide dasarnya, mari gunakan gambar (pembukaan) yang diambil dari situs web NVIDIA.
Dari gambar terlihat bahwa pengertian AI adalah konsep umum dari ML yang pada gilirannya merupakan konsep yang lebih umum dari DL. Tapi tidak hanya. Faktanya, seperti yang kita lihat algoritma pertama dari belajar mendalam mereka lahir lebih dari 10 tahun yang lalu tidak seperti kecerdasan buatan yang lahir sekitar tahun 50-an dengan bahasa pertama seperti LISP dan PROLOG dengan tujuan meniru kemampuan kecerdasan manusia.
Algoritme kecerdasan buatan pertama terbatas pada melakukan sejumlah kemungkinan tindakan tertentu menurut logika tertentu yang ditentukan oleh programmer (seperti dalam permainan catur atau catur).
Melalui Mesin belajar, kecerdasan buatan telah berkembang melalui apa yang disebut algoritma pembelajaran terawasi dan tidak terawasi dengan tujuan menciptakan model matematika pembelajaran otomatis berdasarkan sejumlah besar data input yang merupakan "pengalaman" kecerdasan buatan.
Dalam pembelajaran terawasi, untuk membuat model, perlu melatih AI dengan memberi label pada setiap elemen: misalnya, jika saya ingin mengklasifikasikan buah, saya akan memotret banyak apel yang berbeda dan memberi label model " apel ” jadi untuk pir, pisang, dll.
Dalam pembelajaran tanpa pengawasan, prosesnya akan menjadi sebaliknya: model harus dibuat mulai dari gambar buah yang berbeda, dan model harus mengekstrak label sesuai dengan karakteristik yang dimiliki apel, pir, dan pisang.
Model dari Mesin belajar diawasi sudah digunakan oleh antivirus, filter spam, tetapi juga di bidang pemasaran seperti produk yang disarankan oleh amazon.
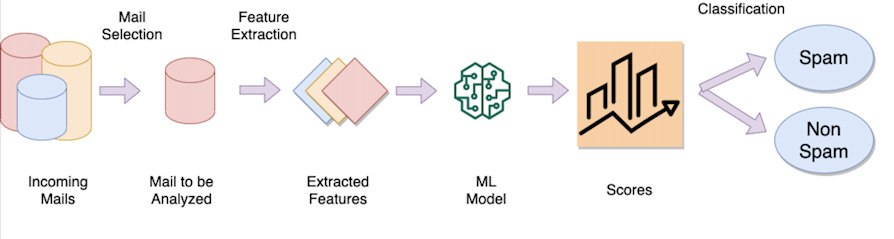
Contoh filter spam
Ide di balik filter spam email adalah untuk melatih model yang "belajar" dari ratusan ribu (jika bukan jutaan) email, dengan melabeli setiap email sebagai Spam atau sah. Setelah model dilatih, operasi klasifikasi melibatkan:
Ekstraksi karakteristik khusus (disebut fitur) seperti, misalnya, kata-kata teks, pengirim email, alamat ip sumber, dll.
Pertimbangkan "bobot" untuk setiap fitur yang diekstraksi (misalnya jika ada 1000 kata dalam teks, beberapa di antaranya mungkin lebih diskriminatif daripada yang lain seperti kata "viagra", "porn", dll. Mereka akan memiliki bobot yang berbeda dari selamat pagi, universitas, dll.)
Jalankan fungsi matematika, yang, dengan mengambil fitur input (kata, pengirim, dll.) dan bobotnya masing-masing, mengembalikan nilai numerik
Periksa apakah nilai ini di atas atau di bawah ambang batas tertentu untuk menentukan apakah email tersebut sah atau dianggap sebagai spam (klasifikasi).
Neuron buatan
Seperti yang disebutkan, Belajar mendalam merupakan cabang dari Mesin belajar. Bedanya dengan Mesin belajar itu adalah kompleksitas komputasi yang membawa sejumlah besar data ke dalam permainan dengan struktur pembelajaran "berlapis" yang terbuat dari jaringan saraf tiruan. Untuk memahami konsep ini, kita mulai dari ide untuk mereplikasi neuron manusia tunggal seperti pada gambar di bawah ini.
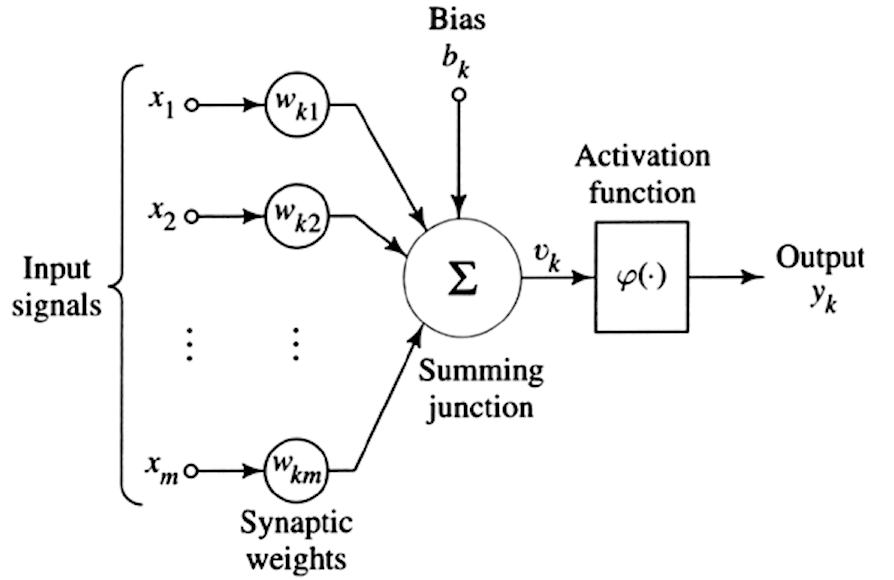
Seperti yang terlihat sebelumnya untuk pembelajaran mesin, kami memiliki serangkaian sinyal input (di sebelah kiri gambar) yang kami kaitkan dengan bobot yang berbeda (Wk), tambahkan "bias" kognitif (bk) yang merupakan semacam distorsi, dan akhirnya menerapkan fungsi aktivasi yaitu fungsi matematika seperti fungsi sigmoid, tangen hiperbolik, ReLU, dll. yang mengambil serangkaian input berbobot dan memperhitungkan bias, mengembalikan output (yk).
Ini adalah neuron buatan tunggal. Untuk membuat jaringan saraf, output dari neuron tunggal dihubungkan ke salah satu input dari neuron berikutnya, membentuk jaringan koneksi yang padat seperti yang ditunjukkan pada gambar di bawah yang mewakili jaringan yang sebenarnya. Jaringan Saraf Dalam.
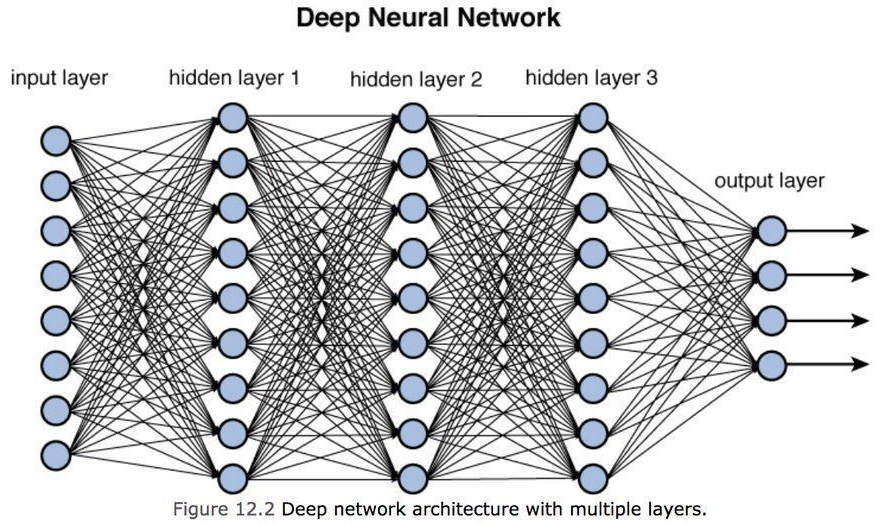
Pembelajaran Mendalam
Seperti yang dapat kita lihat dari gambar di atas, kita memiliki satu set input yang akan dipasok ke jaringan saraf (lapisan input), kemudian tingkat menengah disebut lapisan tersembunyi yang mewakili "lapisan" model dan akhirnya tingkat output yang mampu membedakan ( atau mengenali) satu objek di atas yang lain. Kita dapat menganggap setiap lapisan tersembunyi sebagai kapasitas pembelajaran: semakin tinggi jumlah lapisan perantara (yaitu semakin dalam modelnya), semakin akurat pemahamannya tetapi juga semakin kompleks perhitungan yang harus dilakukan.
Perhatikan bahwa lapisan keluaran mewakili satu set nilai keluaran dengan tingkat probabilitas tertentu, misalnya 95% apel, 4,9% pir dan 0,1% pisang dan seterusnya.
Mari kita bayangkan model DL di bidang visi komputer: lapisan pertama mampu mengenali tepi objek, lapisan kedua mulai dari tepi dapat mengenali bentuk, lapisan ketiga mulai dari bentuk dapat mengenali objek kompleks yang terdiri dari beberapa bentuk, lapisan keempat mulai dari bentuk kompleks dapat mengenali detail dan sebagainya. Dalam mendefinisikan sebuah model, tidak ada jumlah pasti lapisan tersembunyi, tetapi batasannya ditentukan oleh daya yang dibutuhkan untuk melatih model dalam waktu tertentu.
Tanpa terlalu banyak spesifik, pelatihan jaringan saraf memiliki tujuan penghitungan semua bobot dan bias untuk diterapkan ke semua neuron tunggal yang ada dalam model: oleh karena itu terbukti bahwa kompleksitas meningkat secara eksponensial sebagai perantara. lapisan meningkat (lapisan tersembunyi). Untuk alasan ini, prosesor kartu grafis (GPU) telah digunakan untuk latihan: kartu ini cocok untuk beban kerja yang lebih berat karena, tidak seperti CPU, kartu ini dapat melakukan ribuan operasi secara paralel menggunakan arsitektur SIMD (Single Instruction Multiple Data) serta teknologi modern seperti Inti Tensor yang memungkinkan operasi matriks dalam perangkat keras.
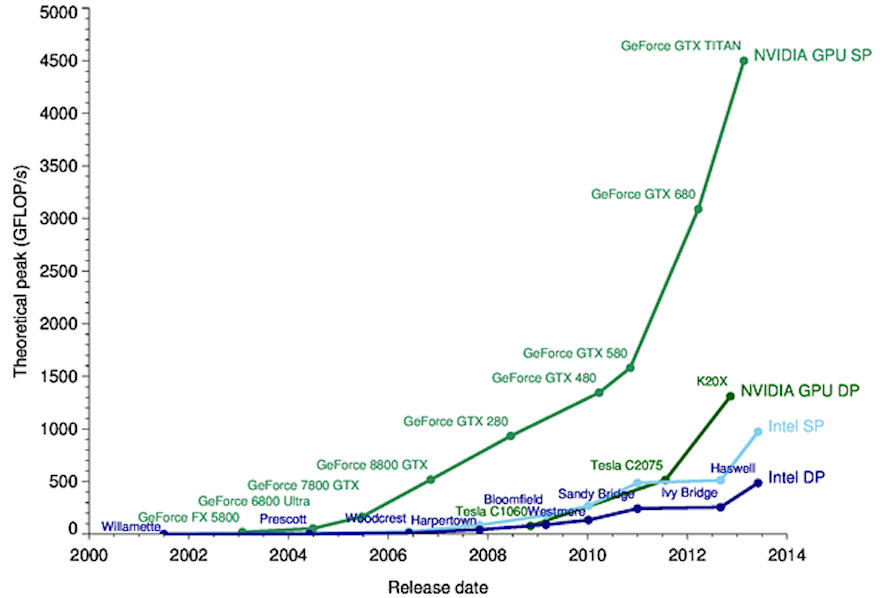
Aplikasi Pembelajaran Mendalam
Dengan memproses data dalam jumlah besar, model ini memiliki toleransi kesalahan dan kebisingan yang tinggi meskipun data tidak lengkap atau tidak akurat. Oleh karena itu mereka memberikan dukungan mendasar dalam setiap bidang ilmu pengetahuan. Mari kita lihat beberapa di antaranya.
Klasifikasi dan keamanan gambar
Dalam kasus kejahatan, memungkinkan pengenalan wajah mulai dari gambar yang diambil oleh kamera pengintai dan membandingkannya dengan database jutaan wajah: operasi ini jika dilakukan secara manual oleh manusia bisa memakan waktu berhari-hari jika tidak berbulan-bulan atau bahkan bertahun-tahun. Selain itu, melalui rekonstruksi gambar beberapa model memungkinkan untuk mewarnai bagian yang hilang dengan akurasi yang sekarang mendekati 100% dari warna aslinya.
Pengolahan Bahasa alami
Kemampuan komputer untuk memahami teks tertulis dan lisan dengan cara yang sama seperti manusia. Di antara sistem yang paling terkenal, Alexa dan Siri tidak hanya mampu memahami, tetapi juga menjawab pertanyaan yang sifatnya berbeda.
Model lain mampu melakukannya analisis sentimen, selalu menggunakan sistem ekstraksi dan opini dari teks atau kata-kata.
Diagnosa medis
Di bidang medis, model-model ini sekarang digunakan untuk melakukan diagnosa, termasuk analisis CT scan atau MRI. Hasil yang pada lapisan keluaran memiliki kepercayaan 90-95%, dalam beberapa kasus, dapat memprediksi terapi untuk pasien tanpa campur tangan manusia. Mampu bekerja 24 jam sehari, setiap hari, mereka juga dapat memberikan dukungan dalam fase triase pasien, secara signifikan mengurangi waktu tunggu di ruang gawat darurat.
Mengemudi otonom
Sistem self-driving membutuhkan pemantauan terus menerus secara real time. Model yang lebih canggih memperkirakan kendaraan yang mampu mengelola setiap situasi mengemudi secara independen dari pengemudi yang kehadirannya di kapal tidak diperkirakan sebelumnya, menyediakan keberadaan hanya penumpang yang diangkut.
Prakiraan dan Profil
Model pembelajaran keuangan yang mendalam memungkinkan kita untuk membuat hipotesis tentang tren pasar masa depan atau untuk mengetahui risiko kebangkrutan suatu institusi lebih akurat daripada yang dapat dilakukan manusia saat ini dengan wawancara, studi, kuesioner, dan perhitungan manual.
Model yang digunakan dalam pemasaran ini memungkinkan kita mengetahui selera orang untuk mengusulkan produk baru, misalnya, berdasarkan asosiasi yang dibuat dengan pengguna lain yang memiliki riwayat pembelian serupa.
Evolusi adaptif
Berdasarkan "pengalaman" yang diunggah, model mampu beradaptasi dengan situasi yang terjadi di lingkungan atau karena input pengguna. Algoritme adaptif menyebabkan pembaruan seluruh jaringan saraf berdasarkan interaksi baru dengan model. Sebagai contoh, mari kita bayangkan bagaimana YouTube menawarkan video dengan tema tertentu tergantung pada periodenya, menyesuaikan hari demi hari dan bulan demi bulan dengan selera dan minat pribadi kita yang baru.
Untuk menyimpulkan, Belajar mendalam itu masih merupakan bidang penelitian yang berkembang pesat. Universitas juga memperbarui program pengajaran mereka tentang mata pelajaran ini yang masih membutuhkan dasar yang kuat dalam matematika.
Keuntungan menerapkan DL ke industri, penelitian, kesehatan, dan kehidupan sehari-hari tidak diragukan lagi.
Namun, kita tidak boleh lupa bahwa ini harus memberikan dukungan kepada manusia dan bahwa hanya dalam beberapa kasus yang terbatas dan sangat spesifik ini dapat menggantikan manusia. Sampai saat ini, pada kenyataannya, tidak ada model "tujuan umum" yang mampu memecahkan semua jenis masalah.
Aspek lain adalah penggunaan template ini untuk tujuan ilegal seperti membuat video Deepfake (lihat artikel), yaitu teknik yang digunakan untuk melapisi gambar dan video lain dengan gambar atau video asli dengan tujuan membuat berita palsu, penipuan, atau porno balas dendam.
Cara terlarang lainnya untuk menggunakan model ini adalah dengan membuat serangkaian teknik yang ditujukan untuk membahayakan sistem komputer seperti pembelajaran mesin permusuhan. Melalui teknik ini dimungkinkan untuk menyebabkan klasifikasi model yang salah (dan dengan demikian menyebabkan model membuat pilihan yang salah), memperoleh informasi tentang kumpulan data yang digunakan (memperkenalkan masalah privasi) atau mengkloning model (menyebabkan masalah hak cipta).
Referensi
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-int...
https://it.wikipedia.org/wiki/Lisp
https://it.wikipedia.org/wiki/Prolog
https://it.wikipedia.org/wiki/Apprendimento_supervisionato
https://www.enjoyalgorithms.com/blog/email-spam-and-non-spam-filtering-u...
https://foresta.sisef.org/contents/?id=efor0349-0030098
https://towardsdatascience.com/training-deep-neural-networks-9fdb1964b964
https://hemprasad.wordpress.com/2013/07/18/cpu-vs-gpu-performance/
https://it.wikipedia.org/wiki/Analisi_del_sentiment
https://www.ai4business.it/intelligenza-artificiale/auto-a-guida-autonom...
https://www.linkedin.com/posts/andrea-piras-3a40554b_deepfake-leonardodi...










